Image transcription humbled me
Plus thoughts on the bitter lesson.
In my last post, I proclaimed that we could automatically transcribe text from social media screenshots, which would be a quick-and-easy win to improve image descriptions and accessibility everywhere. Today, I admit that surprise, surprise: it turns out it was not so easy. An outline:
Promising early results with Tesseract.js
Later challenges
The bitter lesson and how it impacts progress today
—
Promising early results with Tesseract.js
As I mentioned at the end of my previous post,
A huge proportion of images posted on Bluesky are not photos or any kind of visual content; they’re literally just screenshots of text from other social media sites, like X/Twitter, Tumblr, or Reddit.
I noticed this as I reviewed the dataset and kept seeing images like these:

Tesseract.js is an optical character recognition (OCR) library that runs in pure Javascript, including on the client-side. This was appealing to me for a few reasons:
I just wanted to capture text rather than describe visuals, so OCR should be good enough.
Tesseract provides bounding boxes, so it’s possible to detect only images that are mostly text (and ignore other images where there might be important visuals).
Client-side integration makes it easy to run on end users’ devices and present the text to the user to review before posting.
This is the Tesseract.js demo from their website:

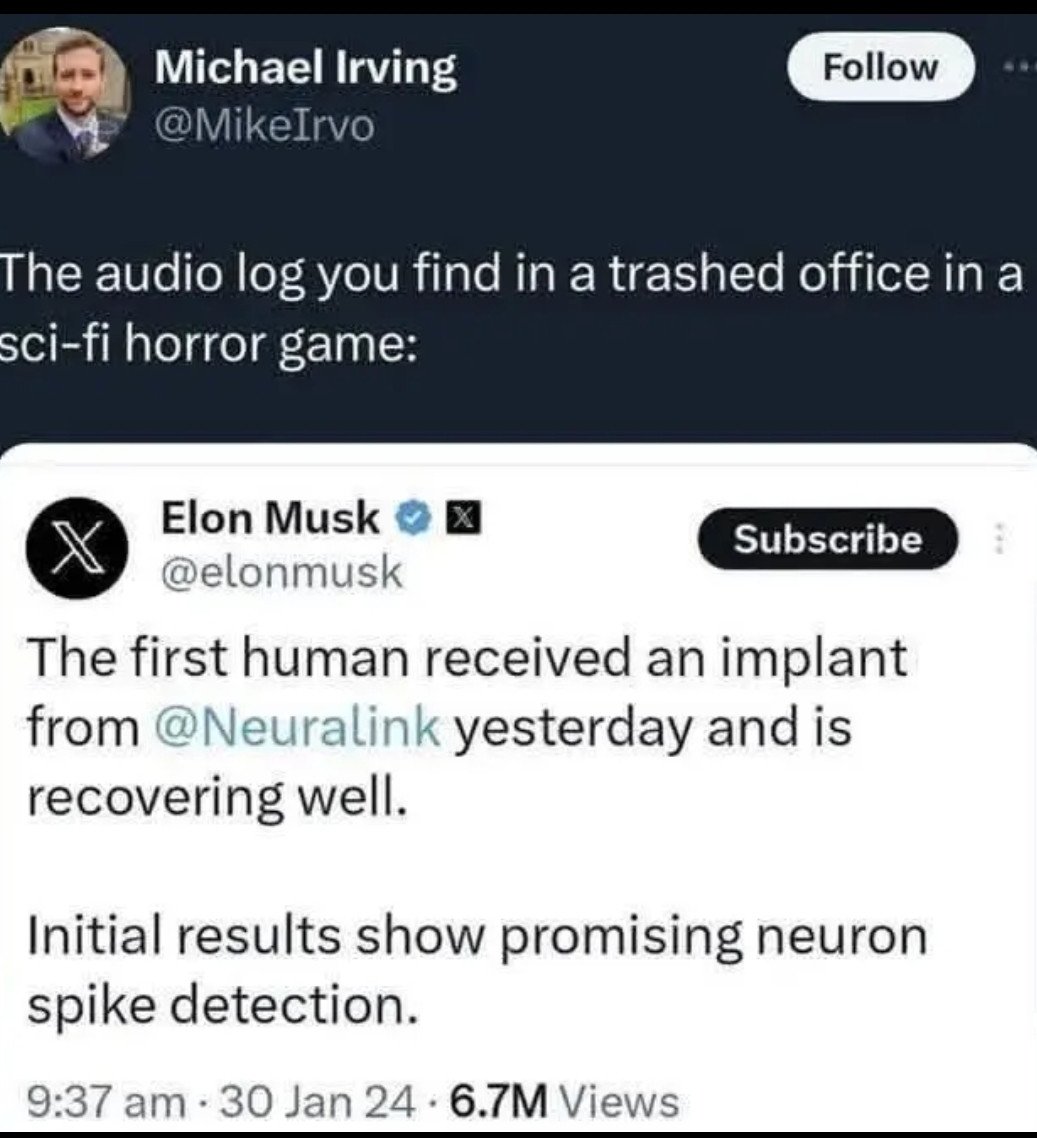
And when I ran similar code over the tweet screenshot above, I got the following output:
2) lauren oes F: @NotABiglerk i'm not falling for that hot take. that's clearly someone with a fetish for getting yelled at. i refuse to participate in that kind of perversion It’s not perfect, but it’s almost there! The UI elements of the profile picture and three-dots context menu are misrecognized and the username is slightly wrong. But the entire body of the tweet is correct. I was excited about this early result and ran it over the first 10,000 image posts recorded in my earlier dataset (image_posts.csv), and found…
Later challenges
…actually, most of the results were not nearly as good. To find social media screenshots, I filtered to a high confidence level (0.80 or higher) and limited to images where Tesseract’s bounding boxes covered at least 20% of the total image area.
Even with these restrictions, it turns out there are lots of variations on social media screenshots. Keeping it just to tweets, I saw various different issues that tanked the quality of the results:
Variations with UI elements like timestamps, reaction counts, and the “Follow” button, that added more noise to the recognized text.
People often screenshot not just a single tweet in isolation, but a series of tweets as a thread, or quote tweets.
Tesseract.js doesn’t handle emojis directly.
Here’s an assortment of tweets that I thought should be good candidates for automated text recognition, but didn’t work well with my approach:
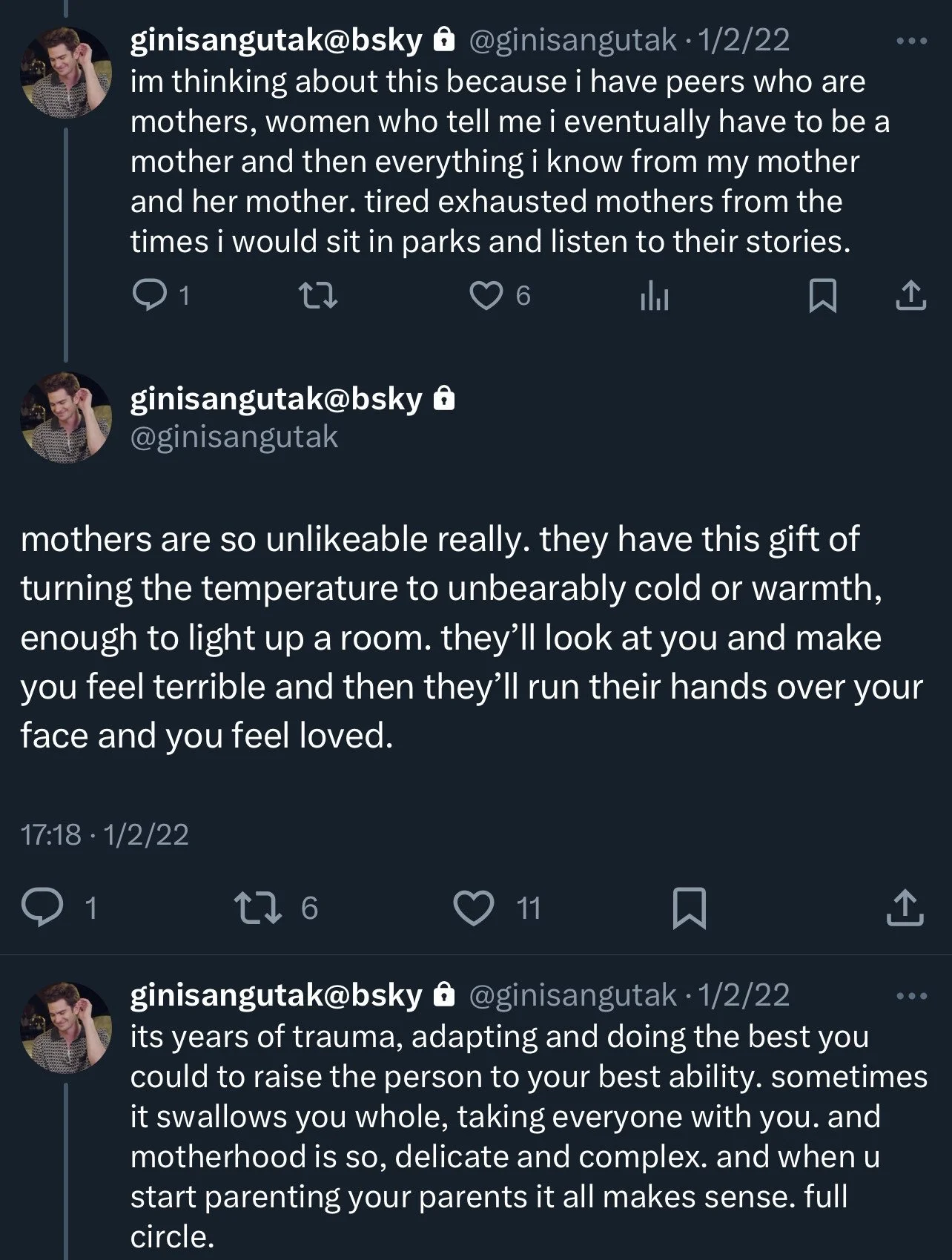
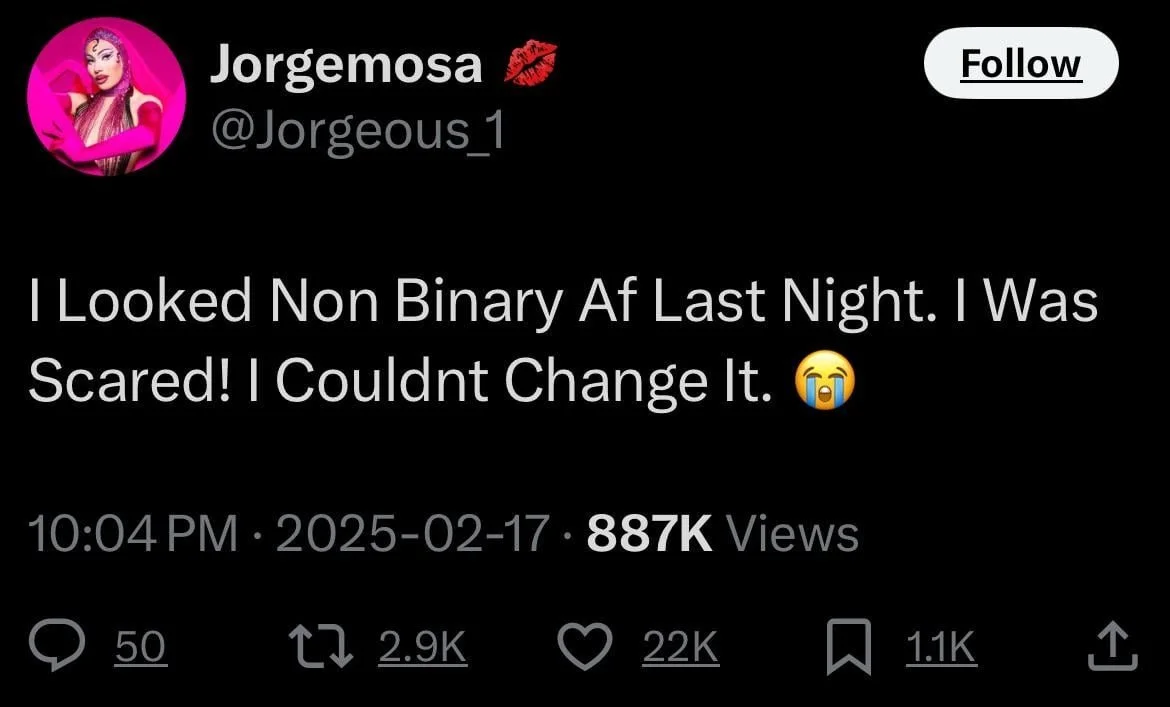
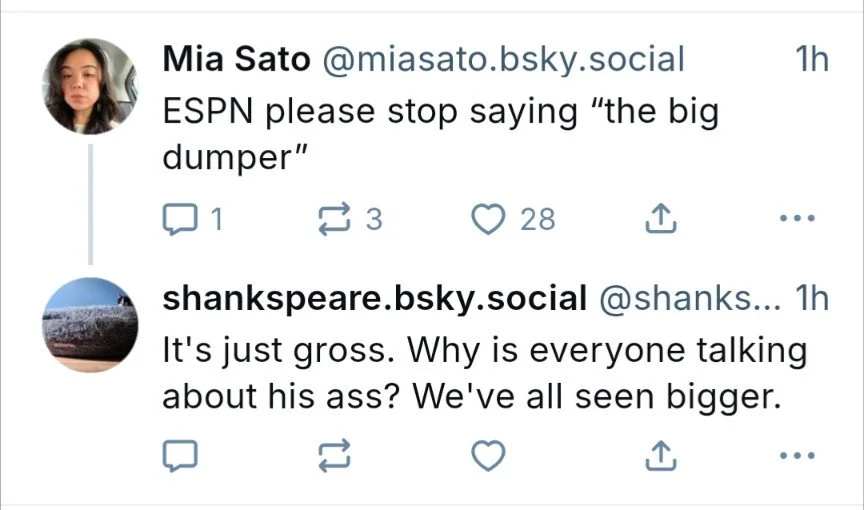
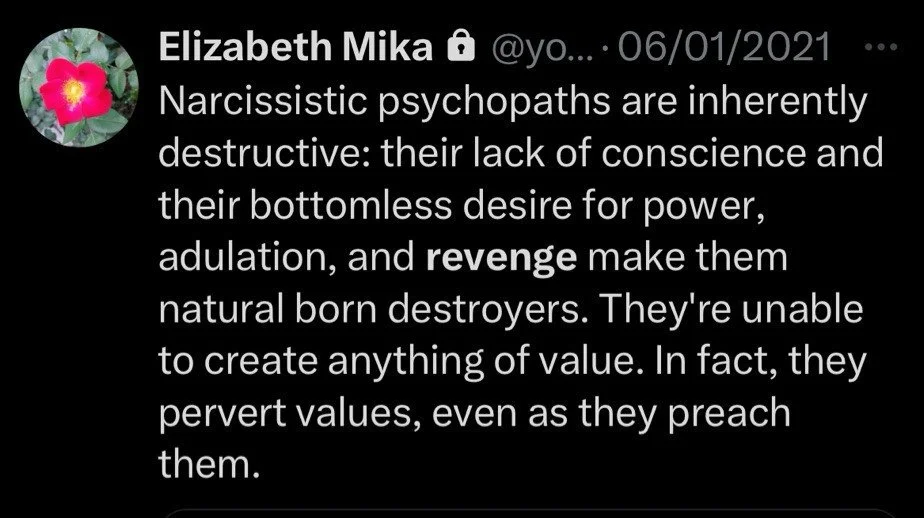
These are not crazy edge cases. They are common examples of real images that people post in the wild. And for each example, I could imagine good old-fashioned image processing that would produce better results.
But then I took a step back. I had already trimmed my dataset from 10,000 images to a little over 100 by filtering for high-confidence, mostly-text images. I’m sure there are other formats that would require special effort. Was it really worth the time to build out social media-specific image processing to automate transcription for 1% of images posted?
I knew it was possible to do better. But the nagging thought kept coming up: isn't this the bitter lesson?
The bitter lesson and its impact on progress today
The bitter lesson is an observation by Rich Sutton that historically, specialized human knowledge has been beaten by better methods that scale well with more compute.
…researchers always tried to make systems that worked the way the researchers thought their own minds worked---they tried to put that knowledge in their systems---but it proved ultimately counterproductive, and a colossal waste of researcher's time, when, through Moore's law, massive computation became available and a means was found to put it to good use.
Rich Sutton: The Bitter Lesson
Indeed, if you slam these images into multi-modal LLMs like ChatGPT or Claude today, which are based on massive computation and training data, they produce just about perfect image transcriptions. They are slower and more compute-intensive than Tesseract.js, which makes them impractical to run on the client-side today. But I can believe that in a few years, there will be more specialized open-source models that will run just fine, and do a better job.
To me, that’s demotivating. Why should I invest now in handcrafted logic to nail automated transcription of these screenshots, when the magic of scaling will catch up in a few years? I could go do something else with my limited time on this planet.
I worry that people feel similarly about just about any problem, and that’s holding us back from real improvements that are available today. As Drew Breunig wrote about the bitter lesson and computer chess (cribbing from Aidan McLaughlin):
Leela is a deep learning model that, “started with no intrinsic chess-specific knowledge other than the basic rules of the game.” It learned by playing chess, at an absurd scale, until it was the best in the world. A true example of the bitter lesson.
Then Stockfish adopted a small, purpose-built search model inside its conventional chess program. Today, Stockfish remains unbeaten – and can run on your iPhone. By not embracing compute as the primary lever, the Stockfish team not only delivered quality, but delivered something everyone can use, often.
Drew Breunig: Does the Bitter Lesson Have Limits?
It feels like a mixed bag that there isn’t truly low-hanging fruit to easily improve the quality and frequency of image descriptions - good that I can’t make a drive-by improvement in a few hours (which would indicate a real lack of attention to accessibility), but also bad that I didn’t make a real improvement. I have been sufficiently humbled.
Can we do better? Of course it’s possible. But to me, the emotional resistance is just as much of a barrier as the technical challenge.
Working on something similar? I’d love to chat - you can reach me at bobbie@digitalseams.com .