Interfaces for representing uncertainty
Software is great at handling facts, but it struggles with the unknown.
In real life, we deal with uncertainty all the time: making tentative plans, calculated bets, or just trying to figure out what’s going on. But most software assumes hard facts. It forces us to be concrete even in squishy situations.
This post explores interfaces for uncertainty. How can software more honestly and helpfully represent the unknown?
A quick overview of what’s ahead:
Why care about uncertainty?
Crosswords and pencils
Maybe-events in my calendar
Climbing the hill of not-knowing
Data-driven models and outcome distributions
Conclusion
Why care about uncertainty?
Lots of things in the world are unknown or uncertain, but most of them don’t matter. The most important unknowns are the ones that affect decisions we might make. In the boldly-named How To Measure Anything, Douglas Hubbard argues that everything you might think of as unknown or “intangible” is still measurable in a meaningful way:
For all practical decision-making purposes, we need to treat measurement as observations that quantitatively reduce uncertainty. A mere reduction, not necessarily elimination, of uncertainty will suffice for a measurement.
Douglas Hubbard, How To Measure Anything
We want to make better decisions, but that doesn’t require waiting for perfect information. Any amount of reducing uncertainty helps us understand the possible outcomes and plan for them.
It can be hard to talk about uncertain scenarios in the abstract, so let me describe a specific one.
A simple model of uncertain future events
Let’s say I’m trying to make plans with my friend Ted. I’ll text him, “Hey, want to get dinner this weekend?”, and a few things will happen:
I’ll wait for his response.
He might respond with a yes, or offer different options.
I might get back an error like “Message undeliverable” from the carrier.
This looks a lot like the Javascript Promise, so let’s use that terminology here. There are three states:
When the Promise is pending, I’m waiting for a response.
If Ted responds, the Promise is fulfilled and I can move on with finalizing the plans.
If I get an error back, the Promise is rejected. I might try to contact him in other ways, or give up entirely.
We can group together fulfilled and rejected into settled, which is useful to talk about situations where the Promise is no longer pending, but we don’t care whether it was fulfilled or rejected.
Here’s the question: how should I represent this Promise while it’s still pending?
Given a better representation of uncertainty, you can act differently
Why should I overcomplicate this? It’s out of my hands, isn’t it? Actually, representing the uncertainty of the Promise directly helps me make better decisions.
I actually have a lot of context about my dinner invite and how it might get settled (or “time out”, as the weekend arrives). Ted usually responds within a day, but sometimes he just forgets to respond. Or maybe the message itself got lost as a casualty of the Android-to-iMessage compatibility mess.
I can do better than just waiting. I’ll just text him again if he doesn’t respond today. That will settle my actual weekend plans, without waiting around in a pending state.
That’s a real technique used in distributed systems! Even within a datacenter, requests can get lost and individual servers can be too overwhelmed to respond. This exact strategy is mentioned in “The Tail at Scale”, an academic paper by Jeffrey Dean and Luiz André Barroso at Google Research:
Hedged requests. A simple way to curb latency variability is to issue the same request to multiple replicas and use the results from whichever replica responds first. We term such requests “hedged requests” because a client first sends one request to the replica believed to be the most appropriate, but then falls back on sending a secondary request after some brief delay.
[…One way to avoid sending too many extra requests] is to defer sending a secondary request until the first request has been outstanding for more than the 95th-percentile expected latency for this class of requests. This approach limits the additional load to approximately 5% while substantially shortening the latency tail.
Jeffrey Dean and Luiz André Barroso: “The Tail at Scale”
That’s exactly like double-texting to settle your plans. What else can we do with this pending state?
Crosswords and pencils
Here’s one simple option for representing the uncertainty of a pending Promise: it’s pending, so it’s completely unknown to me. I can represent that as a single bit of information.
Have you ever done a crossword? Sometimes you might be unsure about a clue, but want to fill in your guess so that you can confirm or deny it later. In the app for the New York Times crossword, you can switch to a “pencil” mode, which displays your letters in a paler shade of gray:

That ghostly word is a visual representation of uncertainty, and a reminder that you can still change. In this case, I tentatively guessed “Like many ingredients in a chopped salad” was “lettuce” - but I’m much more confident that “In an upbeat mood” is “chipper”. I can delete my old guess without worrying about it.
In distributed systems, pencil mode is a kind of “optimistic” choice: there might be a problem with it, but if I discover it later I can undo my mistake. The “pessimistic” equivalent would be to only write down words that I’m completely sure of, which is more efficient if my guesses are often wrong.
Maybe-events in my calendar
I can optimistically put potential dinner plans on my calendar too. It looks like this:

(I’m a religious calendar user; if it’s not on my calendar, I will forget about it.)
But these placeholder Maybe-events aren’t a perfect solution either. At a glance it’s hard for me to distinguish a Maybe-event from my definitely-scheduled haircut appointment. They also don’t play well with automated meeting-scheduling tools like Calendly or Clockwise by default.
The design lab Ink & Switch is exploring this exact problem - how calendars might better reflect ambiguity - in their Sketchy Calendar project. Their lab note asks:
• Is it possible to create interconnected daily, weekly and monthly views like a traditional calendar app?
• How might sketched annotations meaningfully interact with formal calendar events?
• How would shared calendars or calendar invites work in such a semi-structured system?
• How can users personalize their calendars by adding custom dynamic behavior? For example, how might I add a habit tracker or a time tracker, all while preserving the sketchy, personal quality?
Here is a little sneak preview of what a sketchy calendar could look like.

Marcel Goethals and Paul Sonnentag via Ink & Switch: Sketchy Calendar
I’m really looking forward to Ink & Switch’s update here. The calendar captures one part of the problem at personal-scale, and that enables a tight feedback loop for improvements.
Calendar events are an interesting scenario because they’re inherently tied to dates and deadlines. That provides a natural stopping point. What about those unknowns that might float around forever?
Climbing the hill of not-knowing
If you want to build a statue of a clown that juggles flaming torches, you probably shouldn’t start with the clown makeup or the base pedestal. That’s safe and easy work, but ultimately the project relies on the difficult, unknown part.
Every project has unknown parts, and we should tackle them first - even before committing to finishing the project. As a product manager, I like how the “hill chart” from Shape Up (by Basecamp) explicitly shows this dynamic. On the uphill side, you’re still figuring things out. On the downhill side, you’re executing based on what you already understand.

Waiting for someone to text back is uncertain because it depends on their decision. But figuring out how to juggle flaming torches is uncertain because we don’t know how to do it yet. We might never figure out how to do it with our resources.
This comes up in lots of projects: you might identify certain hills that might make the entire project infeasible. You have to take action, “spike” or probe the world, and learn to climb the hill. From the top of the hill, you can decide whether you want to finish or not.
Data-driven models and outcome distributions
Any complicated decision depends on lots of unknowns, so there’s never only one hill to climb. You only have so much time to explore, so what do you prioritize?
To oversimplify How to Measure Anything, it’s pretty cheap to get plausible guesstimates about the possible ranges of each factor, slap them in a spreadsheet, and multiply them out to see what happens. The end result is a distribution of potential outcomes.
I think the most interesting outcome distributions are not smooth curves - especially if they have multiple peaks.
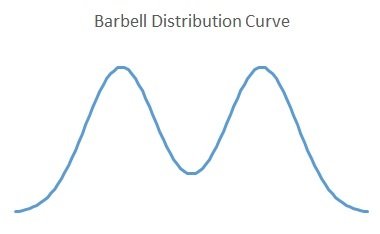
As Exceed Investments explains, biotech companies often have binary outcomes. If the FDA trials succeed, the company stock price will shoot up; if the trials fail, the company might shut down entirely. That one factor might be more important than all the other unknowns! If you’re thinking about investing in a biotech company, you should understand their FDA trials.
One challenge with these kinds of models is creating them. How To Measure Anything literally comes with a collection of Excel spreadsheets so that you can plug and chug numbers.
There’s an ego-related challenge too: it just feels weird to try to guess all of these numbers and pretend that they capture the situation, even if the results are useful. Internet blogger Dynomight even advocates to skip the modeling and just scribble the final graphs instead (it’s worth reading Casey Milkweed’s defense of data-driven models too).

I’d love to see more work here in tools that make it easy for people to guesstimate their input ranges and look at the distribution of possible outcomes. Ideally, the tool should identify which inputs cause the most uncertainty, so you can go try to learn more about those inputs.
Conclusion
Honestly, I don’t have a strong conclusion here. I’m not embarrassed to admit that.
Uncertainty is always going to exist, and we have the opportunity to acknowledge that in our tools instead of forcing false confidence. I like the tools mentioned above, but I think there is plenty more work to be done here.
If you’re working on something related to representing uncertainty, I’d love to hear about it. You can reach me at bobbie@digitalseams.com.
—
Update 2025-08-04: Ted did respond eventually and we managed to meet up for coffee today!